Kafka分区策略有哪些
分区策略
1. 轮询策略
也称 Round-robin 策略,即顺序分配。比如一个主题下有 3 个分区,那么第一条消息被发送到分区 0,第二条被发送到分区 1,第三条被发送到分区 2,以此类推。当生产第 4 条消息时又会重新开始,即将其分配到分区 0,就像下面这张图展示的那样。
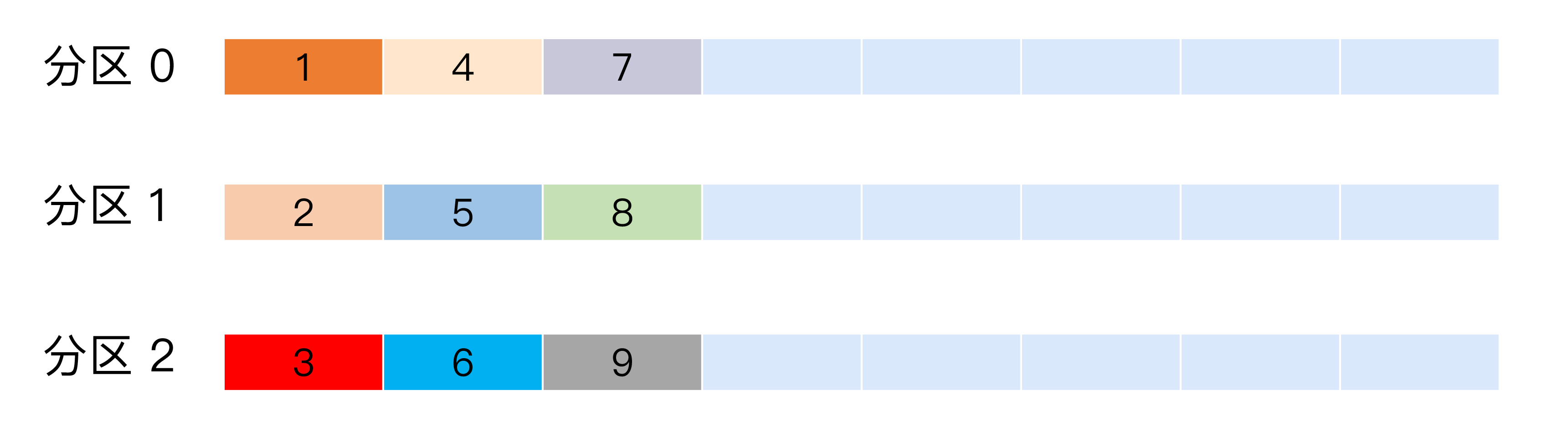
这就是所谓的轮询策略。轮询策略是 Kafka Java 生产者 API 默认提供的分区策略。如果你未指定partitioner.class参数,那么你的生产者程序会按照轮询的方式在主题的所有分区间均匀地“码放”消息。轮询策略有非常优秀的负载均衡表现,它总是能保证消息最大限度地被平均分配到所有分区上,故默认情况下它是最合理的分区策略,也是我们最常用的分区策略之一。
1 | int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster); |
2. 随机策略
本质上看随机策略也是力求将数据均匀地打散到各个分区,但从实际表现来看,它要逊于轮询策略,所以如果追求数据的均匀分布,还是使用轮询策略比较好。事实上,随机策略是老版本生产者使用的分区策略,在新版本中已经改为轮询了。
1 | List partitions = cluster.partitionsForTopic(topic); |
3. 按消息键保序策略
Kafka 允许为每条消息定义消息键,简称为 Key。这个 Key 的作用非常大,它可以是一个有着明确业务含义的字符串,比如客户代码、部门编号或是业务 ID 等;也可以用来表征消息元数据。特别是在 Kafka 不支持时间戳的年代,在一些场景中,工程师们都是直接将消息创建时间封装进 Key 里面的。一旦消息被定义了 Key,那么你就可以保证同一个 Key 的所有消息都进入到相同的分区里面,由于每个分区下的消息处理都是有顺序的,故这个策略被称为按消息键保序策略,如下图所示。
1 | List partitions = cluster.partitionsForTopic(topic);return Math.abs(key.hashCode()) % partitions.size(); |
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 二九的博客!
相关推荐

2025-03-03
Kafka如何完成数据持久化
一、概念Data目录存储二进制消息数据 配置项: 1log.dirs=/Users/vhicool/app-template/kafka-2broker/kafka/broker1 kafka日志末尾附加记录,并且每个日志也被分割成segment。segment有助于删除旧记录,提高性能等等。因此,日志是由segment文件组成的记录的逻辑序列。 Kafka 主题被拆分为多个partition,记录将追加到这些partition。每个分区都可以定义为一个工作单元,而不是存储单元,因为它被客户端用来交换记录。分区进一步拆分为多个segment,这些segment是磁盘上的实际文件。拆分为多个segment确实有助于提高性能(当磁盘上的记录被删除或使用者开始从特定偏移量使用时,大型、未分段的文件速度较慢且更容易出错)。查看broker磁盘,每个主题分区都是一个目录,其中包含相应的 segment 文件和其他文件。以...
2025-01-25
Kafka如何保证无消息丢失
Kafka 只对“已提交”的消息(committed message)做有限度的持久化保证。 已提交 Broker 成功地接收到一条消息并写入到日志文件后,它们会告诉生产者程序这条消息已成功提交。此时,这条消息在 Kafka 看来就正式变为“已提交”消息了。 有限度的持久化保证Kafka 不可能保证在任何情况下都做到不丢失消息。假如你的消息保存在 N 个 Kafka Broker 上,那么这个前提条件就是这 N 个 Broker 中至少有 1 个存活。只要这个条件成立,Kafka 就能保证你的这条消息永远不会丢失。 最佳实践 不要使用 producer.send(msg),而要使用 producer.send(msg, callback)。记住,一定要使用带有回调通知的 send 方法。 设置 acks = all。acks 是 Producer 的一个参数,代表了你对“已提交”消息的定义。如果设置成 all,则表明所有副本 Broker...
2025-03-17
kafka性能调优
操作系统调优 挂载(Mount)文件系统时禁掉 atime 更新 atime 的全称是 access time,记录的是文件最后被访问的时间。记录 atime 需要操作系统访问 inode 资源,而禁掉 atime 可以避免 inode 访问时间的写入操作,减少文件系统的写操作数。你可以执行 mount -o noatime 命令进行设置。 文件系统选择 至少选择ext4 或 XFS,尤其是 XFS 文件系统,它具有高性能、高伸缩性等特点,特别适用于生产服务器。 ZFS 多级缓存的机制能够帮助 Kafka 改善 I/O 性能 swap 空间的设置 建议将swappiness 设置成一个很小的值,比如 1~10 之间,以防止 Linux 的 OOM Killer 开启随意杀掉进程 临时设置:sudo sysctl vm.swappiness=N 永久设置:修改 /etc/sysctl.conf 文件,增加 vm.swappiness=N,然后重启机器 ulimit -n 如果设置得太小,你会碰到 Too Many...
2025-01-07
Kafka常用命令,日常运维必备
主题 创建主题 –zookeeper 会绕过 Kafka 的安全体系。这就是说,即使你为 Kafka 集群设置了安全认证,限制了主题的创建,如果你使用 –zookeeper 的命令,依然能成功创建任意主题,不受认证体系的约束 1bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 2 --topic test 直接使用–bootstrap-server 与集群进行交互 1bin/kafka-topics.sh --bootstrap-server broker_host:port --create --topic my_topic_name --partitions 1 --replication-factor 1 发送消息 1bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test 查询指定topic 1bin/kafka-topics.sh...
2025-02-23
Kafka消费组如何进行重平衡
一、概念Rebalance 就是让一个 Consumer Group 下所有的 Consumer 实例就如何消费订阅主题的所有分区达成共识的过程。在 Rebalance 过程中,所有 Consumer 实例共同参与,在协调者组件的帮助下,完成订阅主题分区的分配。在整个过程中,所有实例都不能消费任何消息,因此它对 Consumer 的 TPS 影响很大。 Coordinator 它专门为 Consumer Group 服务,负责为 Group 执行 Rebalance 以及提供位移管理和组成员管理等。Consumer 端应用程序在提交位移时,其实是向 Coordinator 所在的 Broker 提交位移。同样地,当 Consumer 应用启动时,也是向 Coordinator 所在的 Broker 发送各种请求,然后由 Coordinator 负责执行消费者组的注册、成员管理记录等元数据管理操作。 所有 Broker 都有各自的 Coordinator 组件,从broker上找到当前分组的协调器, 你可以理解为找到位移主题所在的broker...
2025-02-13
Kafka消费组如何提交位移
Consumer 需要向 Kafka 汇报自己的位移数据,这个汇报过程被称为提交位移(Committing Offsets)。Consumer 需要为分配给它的每个分区提交各自的位移数据。 一、位移提交方式从用户的角度来说,位移提交分为自动提交和手动提交;从 Consumer 端的角度来说,位移提交分为同步提交和异步提交。 1. 位移提交控制enable.auto.commit:Consumer 端位移提交配置,默认值true,自动提交位移。 auto.commit.interval.ms:它的默认值是 5 秒,表明 Kafka 每 5 秒会为你自动提交一次位移 2. 自动提交位移Kafka 会保证在开始调用 poll 方法时,提交上次 poll 返回的所有消息。从顺序上来说,poll 方法的逻辑是先提交上一批消息的位移,再处理下一批消息,因此它能保证不出现消费丢失的情况。但自动提交位移的一个问题在于,它可能会出现重复消费 1234567891011121314Properties props = new Properties(); ...