Kafka如何完成数据持久化
一、概念
Data目录存储二进制消息数据
配置项:
1 | log.dirs=/Users/vhicool/app-template/kafka-2broker/kafka/broker1 |
kafka日志末尾附加记录,并且每个日志也被分割成segment。segment有助于删除旧记录,提高性能等等。因此,日志是由segment文件组成的记录的逻辑序列。
Kafka 主题被拆分为多个partition,记录将追加到这些partition。每个分区都可以定义为一个工作单元,而不是存储单元,因为它被客户端用来交换记录。分区进一步拆分为多个segment,这些segment是磁盘上的实际文件。拆分为多个segment确实有助于提高性能(当磁盘上的记录被删除或使用者开始从特定偏移量使用时,大型、未分段的文件速度较慢且更容易出错)。查看broker磁盘,每个主题分区都是一个目录,其中包含相应的 segment 文件和其他文件。以 test主题及其生产者和消费者为例,下面是目录的示例。
比如topic:test有2个partition,那么他的数据目录格式为{topic}-{partition},即:test-0、test-1
存储目录结构
1 | . |
上面展示了主题:test文件目录,里面的包含的文件有
.log:文件存储真实数据segment,包含特定偏移量的记录。文件的名称定义该日志中记录的起始偏移量。.index:日志索引文件,里面包含数据索引,该索引将逻辑偏移量(实际上是记录的 ID)映射到 .log 文件中记录的字节偏移量。它用于访问日志中指定偏移量的记录,而无需扫描整个 .log 文件。格式
1
2
3
4
5offset: 53 position: 4124
offset: 106 position: 8264
...
offset: 1302 position: 103050
offset: 1354 position: 107210关键用法:kafka使用稀疏索引来达到快速检索与空间使用上的平衡,技能快速检索数据,同步使index文件尽量小
.timeindex:消息的时间索引文件.snapshot:文件包含有关用于避免重复记录的序列 ID 的生产者状态的快照。当选出新领导人后,首选领导人回来并需要这样的状态才能再次成为领导人时,就会使用它leader-epoch-checkpoint:
数据日志(.log)文件
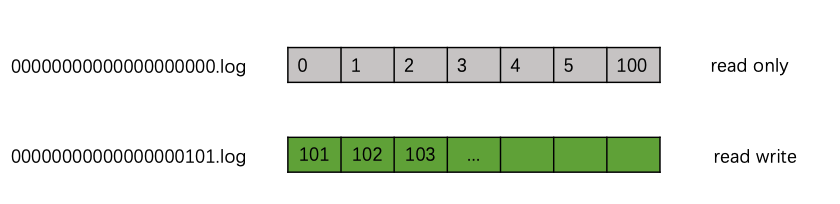
在test-0的数据目录中,我们可以看到两个segment,00000000000000000000.log和00000000000000000101.log,其中第一个segment 00000000000000000000.log 包含的数据索引是0-100,第二个segment:00000000000000000101.log的数据起始索引是101,为活跃的segment。
活跃segment是唯一为读取和写入操作打开的文件,它是追加新传入记录的segment。一个partition只有一个活跃segment。非活动区segment是只读的,由读取旧记录的consumer访问。每个segment大小是固定的(通过segment.bytes=16384指定),当活跃segment已满时,意味着它将以只读模式并重新以读写模式打开创建一个新的segment文件,成为活跃segment,依次滚动
我们可以通过 kafka 自带的工具,可以查看 .log 等文件的内容
1 | bin/kafka-run-class.sh kafka.tools.DumpLogSegments --print-data-log --files ./xxx.log |
参数:
- –print-data-log:输出payload数据
- –key-decoder-class:key的反序列化方式,默认String
- –max-message-size:最大消息条数,默认5242880
1 | Dumping 00000000000000000000.log |
索引文件(.index)
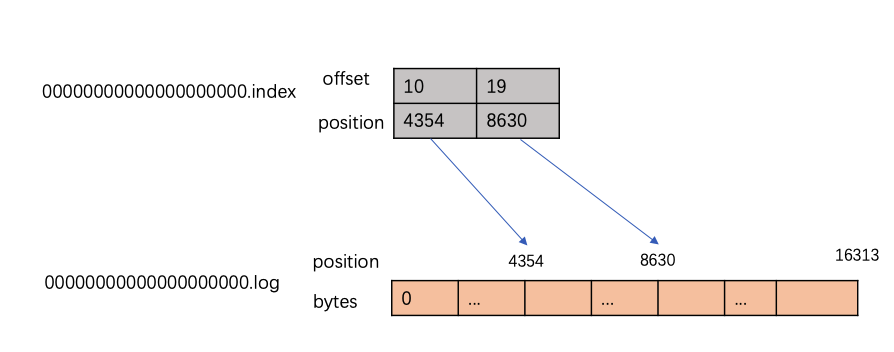
如前所述,.index 文件包含一个索引,该索引将逻辑偏移量映射到 .log 文件中记录的字节偏移量。此映射并不是将每条记录都做映射,而是通过稀疏索引的方式。比如主题:test在00000000000000000101.log文件中一共写入了24条记录,而实际上只生成了两个索引。在下图中,可以看到,对于日志文件中存储的 23条记录,相应的索引只有 2个条目。
我们通过kafka自带工具,查看.index文件的内容
1 | ~/Applications/kafka_2.11-2.2.1/bin/kafka-run-class.sh kafka.tools.DumpLogSegments --print-data-log --deep-iteration --files 00000000000000000000.index |
输出
1 | dumping 00000000000000000000.index |
二、不同版本的数据文件格式
1. V0版本( 0.10.0 )
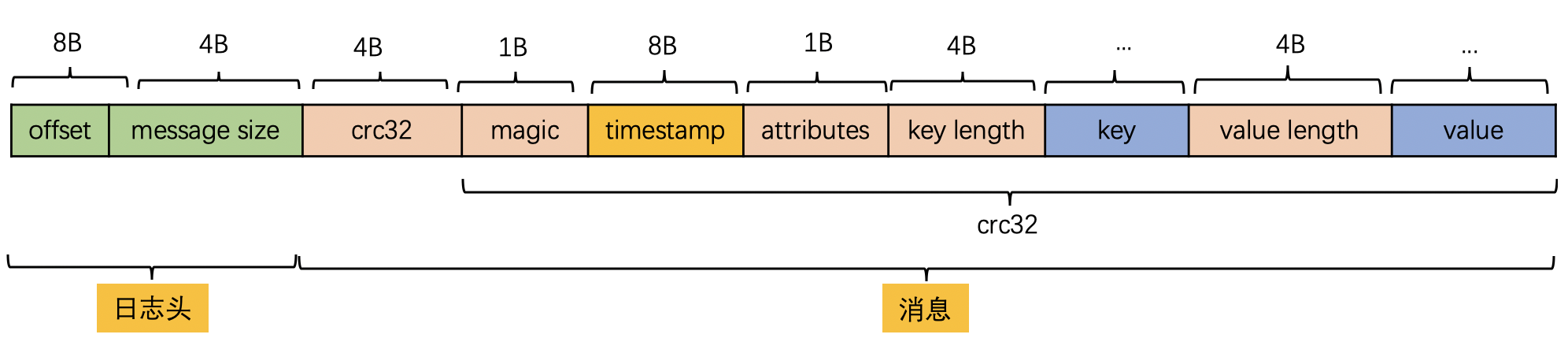
offset : 用来表示它在 Partition分区中的偏移量
长度:8B
message size :消息的大小
长度:4B
crc32 :crc32校验值。校验范围为magic至value之间
长度:4B
magic:日志格式版本号,此版本的magic值为0
长度:1B
attributes:消息的属性。总共占1个字节,低3位表示压缩类型:0 表示NONE、1表示GZIP、2表示SNAPPY、3表示LZ4(LZ4自Kafka 0.9.x 版本引入),其余位保留
长度:1B
key length:表示消息的key的长度,如果为-1,则没有设置key
长度:4B
key :可选,如果没有key则无此字段。
长度:不定长
value length :实际消息体的长度。如果为-1,则消息为空
长度:4B
value :消息体
长度:不定长
V0设计缺陷 :
V0 版本的日志格式由于没有保存时间信息导致 Kafka 无法根据消息的具体时间进行判断,在进行清理日志的时候只能使用日志文件的修改时间导致可能会被误删
2. V1 版本(V0.10.0-V0.11.0)
相较于V0版本,V1版本新增timestamp信息,表示消息的时间戳。用于消息保存策略(按照时间保存)、文件拆分以及数据延迟等
3. V0、V1版本缺陷
通过上面我们分析画出的 V0、V1 版本日志格式,我们会发现它们在设计上的一定的缺陷,比如:
空间使用率低:无论 key 或 value 是否存在,都需要一个固定大小 4 字节去保存它们的长度信息,当消息足够多时,会浪费非常多的存储空间
只保存最新消息位移
冗余的 CRC 校验:即使是批次发送消息,每条消息也需要单独保存 CRC
4. 消息压缩
实际上,Kafka发送消息的时候并不是一条一条消息进行发送,而是通过消息集(message set)的方式批量发送。为了实现更好的性能,Kafka支持了消息压缩功能,具体来讲就是压缩消息集。一般来说,压缩解压过程是:生产者发送压缩消息集,broker端保存压缩消息集,消费者解压消息集进行消费。这样就能减少网络IO消耗,提升整体性能。
生产者可以通过配置compression.type参数来开启压缩功能,可配置的值为gzip、snappy和lz4,分别对应了三种压缩算法。压缩消息时,将整个消息集进行压缩作为一个内层消息,作为外层消息的value。并且将原来消息集最大的offset作为外层消息的offset,而内层消息的offset永远从0开始。
5. V2版本(0.11.0)
Kafka从0.11.0版本开始使用v2版本消息格式,v2版本的改动非常大。首先是引入了变长整形(varinits),做到了数值越小,占用的字节数就越少,从而大大节省了空间。
v2版本中的消息集换成了Record Batch,其内部也包含一条或者多条消息。v2完整消息格式如下:
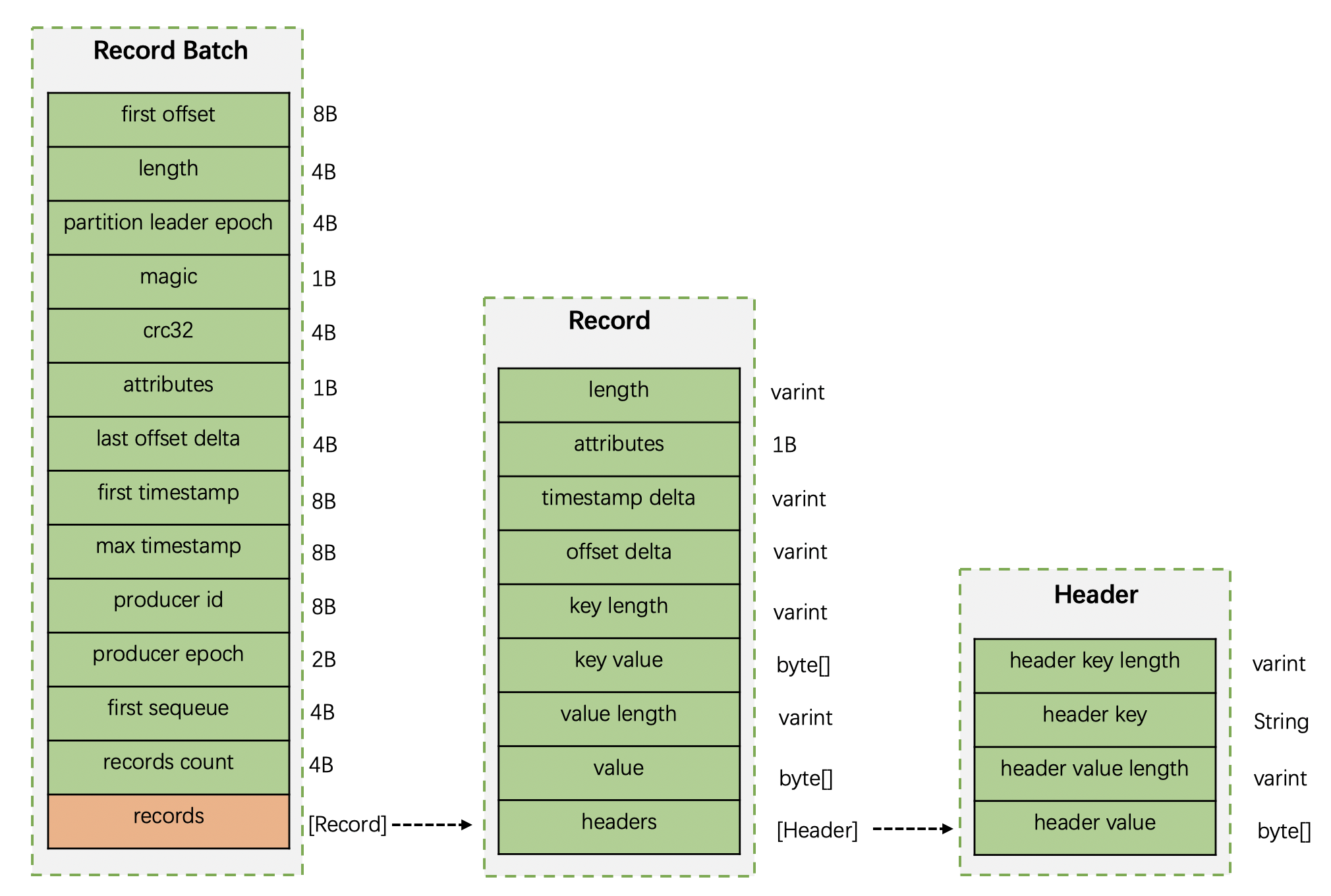
RecordBatch 的关键字段:
- first offset:表示当前RecordBatch的起始偏移量。
- length:计算从
partition leader epoch到末尾的长度。 - partition leader epoch:分区leader纪元,可以看做是分区leader的版本号或者更新次数。
- magic:消息格式版本号,v2版本是2。
- crc32:crc32校验值。
- attributes:消息属性,这里占用2个字节。低三位表示压缩格式,第4位表示时间戳类型,第5位表示此RecordBatch是否在事务中,第6位表示是否为控制消息。
- last offset delta:RecordBatch中最后一个Record的offset与first offset的差值。主要用于broker确保RecordBatch中Recoord组装的正确性。
- first timestamp:RecordBatch中第一条Record的时间戳。
- max timestamp:RecordBatch中最大的时间戳。一般情况是最后一条Record的时间戳。
- producer id:PID,用来支持事务和幂等。暂不解释。
- producer epoch:用来支持事务和幂等。暂不解释。
- first sequeue:用来支持事务和幂等。暂不解释。
- records count:RecordBatch中record的个数。
- records:消息记录集合
Record 的关键字段:
- length:消息总长度
- attributes:弃用。这里仍然占用了1B大小,供未来扩展。
- timestamp delta:时间戳增量。
- offset delta:偏移量增量。保存与RecordBatch起始偏移量的差值。
- key length:消息key长度。
- key value:消息key的值。
- value length:消息体的长度。
- value:消息体的值。
- headers:消息头。用来支持应用级别的扩展。
Header 的关键字段:
- header key length:消息头key的长度。
- header key:消息头key的值。
- header value length:消息头值的长度。
- header value:消息头的值。
V2 版本的消息批次(RecordBatch),相比 V0、V1 版本主要有以下变动:
将 CRC 值从消息中移除,被抽取到消息批次中。
增加了 procuder id、producer epoch、序列号等信息主要是为了支持幂等性以及事务消息的。
使用增量形式来保存时间戳和位移。
消息批次最小为 61 字节,比 V0、V1 版本要大很多,但是在批量消息发送场景下,会提供发送效率,降低使用空间。
三、日志清理机制
Kafka 将消息存储到磁盘中,随着写入数据不断增加,磁盘占用空间越来越大,为了控制占用空间就需要对消息做一定的清理操作。从上面 Kafka 存储日志结构分析中每一个分区副本(Replica)都对应一个 Log,而 Log 又可以分为多个日志分段(LogSegment),这样就便于 Kafka 对日志的清理操作。
Kafka提供了两种日志清理策略:
日志删除(Log Retention):按照一定的保留策略直接删除不符合条件的日志分段(LogSegment)。
日志压缩(Log Compaction):针对每个消息的key进行整合,对于有相同key的不同value值,只保留最后一个版本。
这里我们可以通过 Kafka Broker 端参数 log.cleanup.policy 来设置日志清理策略,默认值为 delete,即采用日志删除的清理策略。如果要采用日志压缩的清理策略,就需要将 log.cleanup.policy 设置为 compact,这样还不够,必须还要将log.cleaner.enable(默认值为 true)设为 true。
如果想要同时支持两种清理策略, 可以直接将 log.cleanup.policy 参数设置为delete,compact。
1. 日志删除
Kafka 的日志管理器(LogManager)中有一个专门的日志清理任务通过周期性检测和删除不符合条件的日志分段文件(LogSegment),这里我们可以通过 Kafka Broker 端的参数 log.retention.check.interval.ms 来配置,默认值为300000,即5分钟。
在 Kafka 中一共有3种保留策略:
基于时间策略
日志删除任务会周期检查当前日志文件中是否有保留时间超过设定的阈值(retentionMs) 来寻找可删除的日志段文件集合(deletableSegments)。
阈值配置优先级: log.retention.ms > log.retention.minutes > log.retention.hours,默认情况只会配置 log.retention.hours 参数,值为168即为7天。
依据 :segment中最大的时间戳largestTimeStamp,首先要查询该日志分段所对应的时间戳索引文件,查找该时间戳索引文件的最后一条索引数据,如果时间戳值大于0,则取值,否则才会使用最近修改时间(lastModifiedTime)
删除步骤:
首先从 Log 对象所维护的日志段的跳跃表中移除要删除的日志段,用来确保已经没有线程来读取这些日志段。
将日志段所对应的所有文件,包括索引文件都添加上
.deleted的后缀。最后交给一个以
delete-file命名的延迟任务来删除这些以.deleted为后缀的文件。默认1分钟执行一次, 可以通过 file.delete.delay.ms 来配置
基于日志大小策略
日志删除任务会周期检查当前日志大小是否超过设定的阈值
retentionSize来寻找可删除的日志段文件集deletableSegments其中 retentionSize 这里我们可以通过 Kafka Broker 端的参数
log.retention.bytes来设置, 默认值为-1,即无穷大这里需要注意的是 log.retention.bytes 设置的是Log中所有日志文件的大小,而不是单个日志段的大小。单个日志段可以通过参数 log.segment.bytes 来设置,默认大小为1G
基于日志起始偏移量
首先计算日志文件的总大小Size和retentionSize的差值,即需要删除的日志总大小
然后从日志文件中的第一个日志段开始进行查找可删除的日志段的文件集合(deletableSegments)
找到后就可以进行删除操作了
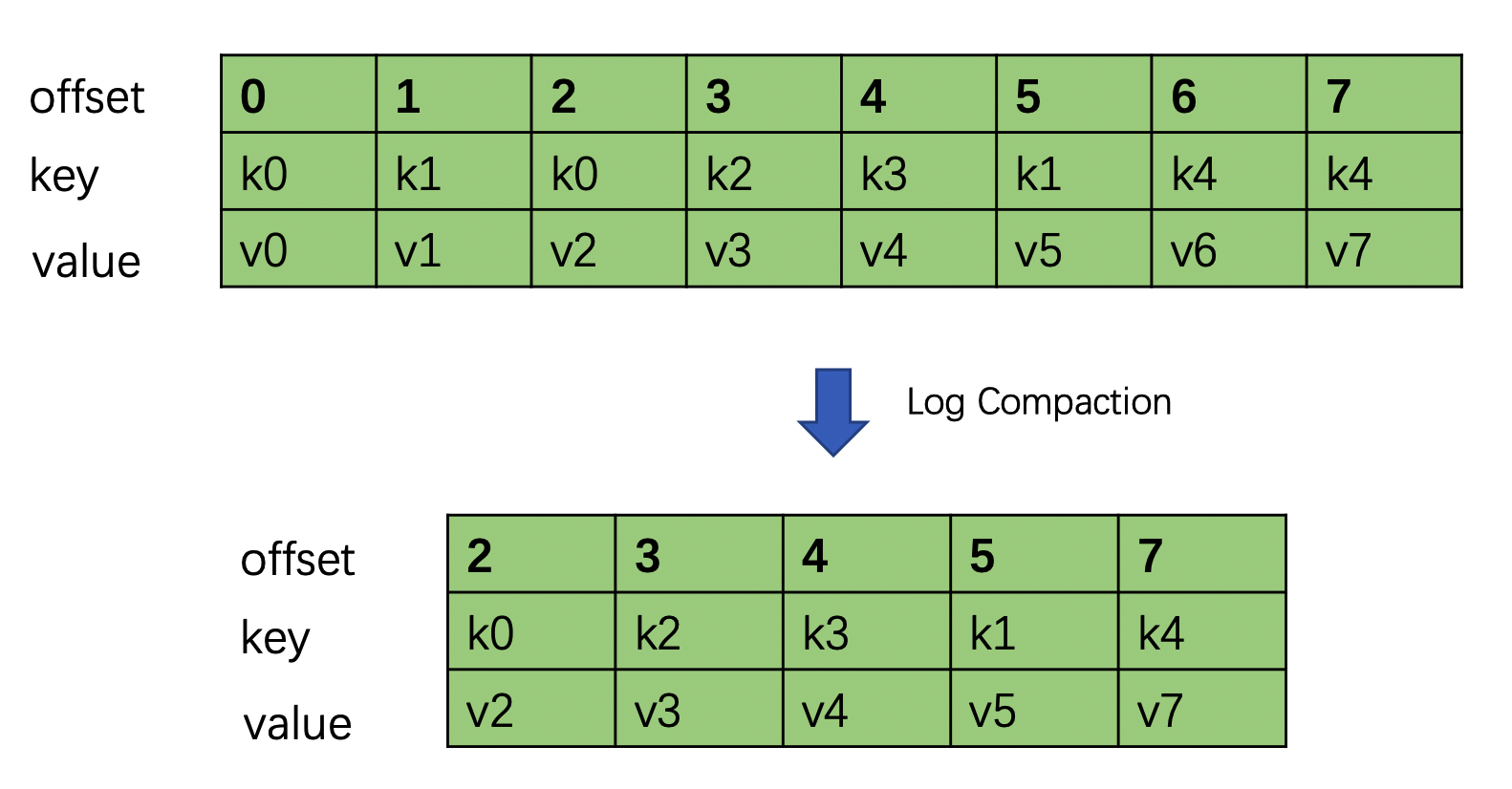
四、日志压缩
日志压缩 Log Compaction 对于有相同key的不同value值,只保留最后一个版本。如果应用只关心 key 对应的最新 value 值,则可以开启 Kafka 相应的日志清理功能,Kafka会定期将相同 key 的消息进行合并,只保留最新的 value 值。
Log Compaction 可以类比 Redis 中的 RDB 的持久化模式。我们可以想象下,如果每次消息变更都存 Kafka,在某一时刻, Kafka 异常崩溃后,如果想快速恢复,可以直接使用日志压缩策略, 这样在恢复的时候只需要恢复最新的数据即可,这样可以加快恢复速度。